

< Back
Article
Open-Sourcing Code Indexer Loop: a dynamic vector index for your code
Sep 7, 2023
tl;dr: we're open sourcing an Apache 2.0 licensed Python library that builds and maintains a dynamic vector index of your source code on top of LlamaIndex, LangChain, and ChromaDB.
Show me the code! GitHub project: definitive-io/code-indexer-loop
At Definitive we spend a lot of time thinking about how to make it easier for our customers to take advantage of LLMs and proprietary data to supercharge their products and internal teams.
As a deeply technical team we engage with open source projects & communities every day. If you've been paying attention to advances in LLM powered applications you can't help but be impressed by the sheer speed at which things are progressing. From the explosion in choice of LLMs (Llama, PaLM, Adept, Falcon, Anthropic, OpenAI) themselves, to schema and API calling abstractions like LangChain, to vector databases like Pinecone, Weaviate, ChromaDB, and Qdrant, to retrieval frameworks like LlamaIndex, to observability products like LangSmith, Helicone, HoneyHive, and pezzo, to agent projects like AutoGPT, gpt-engineer, and E2B.
That enormous amount of activity is supercharging every developer and allows everyone to become more ambitious, raise the ceiling of what's possible, and build mind blowing solutions that wouldn't even be imagined due to sheer impossibility just a few years ago.
Today, we're hoping to contribute to that progress by sharing a building block, a library component if you will, that abstracts away a common but crucial task for many LLM applications.
We're releasing Code Indexer Loop: a vector based code index that continuously monitors and indexes source code files in any* language. A simple pip install code-indexer-loop install-able Python library you can add to your project.
Oftentimes when populating the context window of a broader LLM call chain you need to retrieve the relevant information into it in order for the LLM to reason correctly about whatever it's tasked to do.
Searching through code is relevant in many LLM applications. From developer focused applications like GitHub's Copilot to more data oriented applications that generate SQL and Python like the applications we're building at Definitive.
With Code Indexer Loop you can forget about laborious task of breaking down long source code into semantically well-defined smaller code chunks and dynamically and efficiently updating your vector database of choice when modifications of source code inevitably occur somewhere in the source code directory you're trying to search through.
With the simplest possible API we allow you to search for chunks or full source code documents across directories containing 100s or 1000s of source code files to find exactly the right source code to use in your prompt for better task performance.
Even as files get added and removed, our watchdog based indexer will continuously remove, generate and add embeddings for the semantically valid code chunks that live in your directory's source code files.
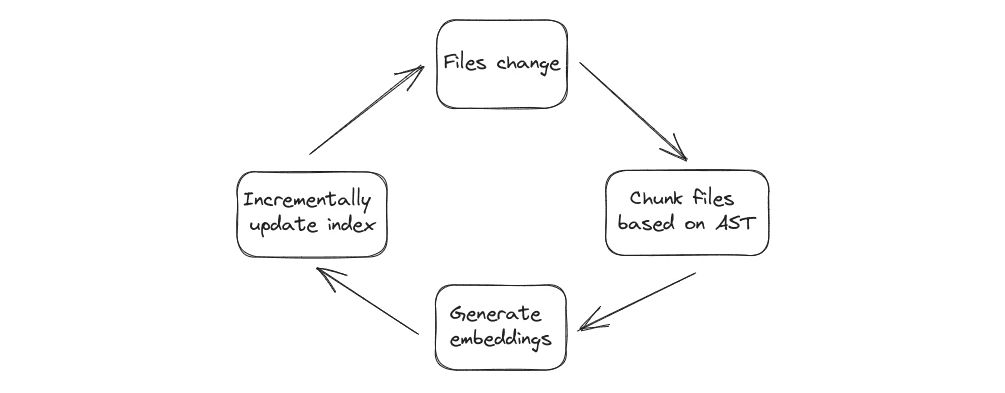
Semantically what? When slicing up source code files to find only the relevant pieces of code you don't want to cut up strings of source code mid-way in a function, class or even multi-line statement declaration. Using node traversal we can use the AST of the parsed source code files to make sure this never happens.
Without AST based chunking
With AST based chunking
In addition we use md5 based file hashing to efficiently check whether files need to be re-chunked/re-embedded:
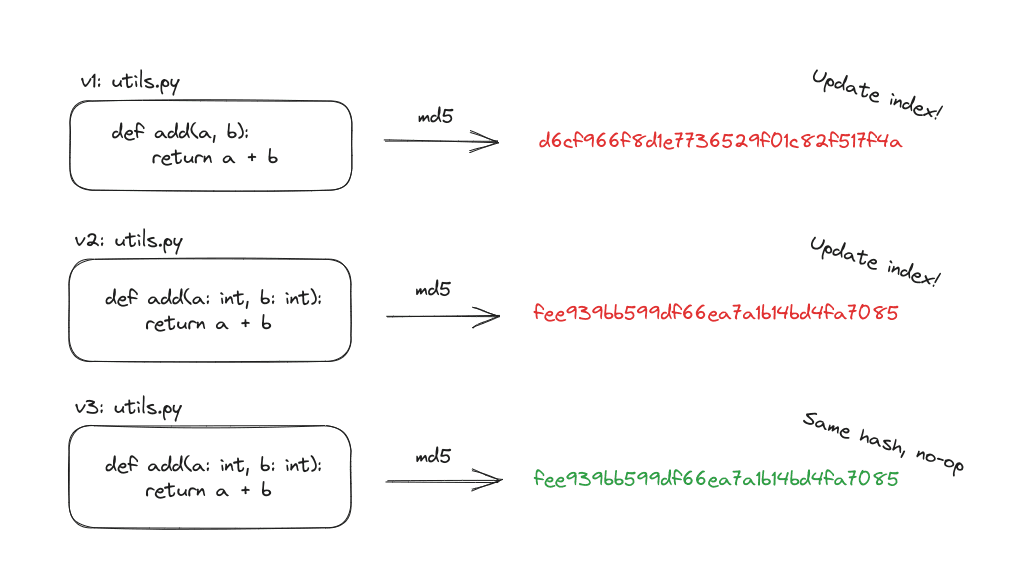
We couldn't be more excited to bring this to the Open Source community as an Apache 2.0 licensed project. We'll be making it more robust over time and hopefully we can work with the community to bundle forces to improve the performance, extensibility and accuracy of the Code Indexer Loop project in the future.
Check out the project on GitHub and star it for support!
https://github.com/definitive-io/code-indexer-loop
* Any programming language supported by the tree-sitter project